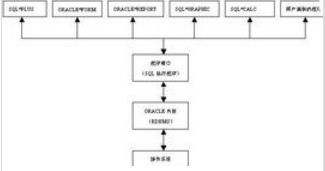
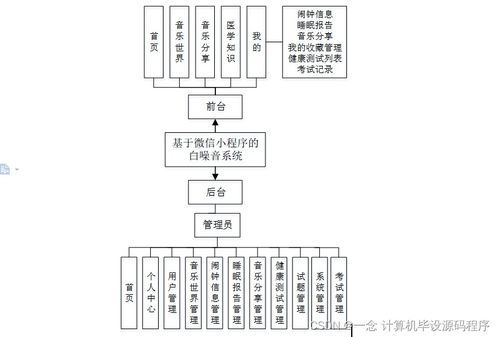
在当今数字化时代,服务器作为计算机系统服务的核心,其稳定运行至关重要。无论是企业级应用还是互联网服务,高效的服务器运维能力直接决定了系统服务的质量。本文将从实战角度出发,分享一些简单易行却效果显著的服务器运维技巧,帮助运维人员提升系统服务的可靠性和效率。
一、定期健康检查与日志分析
服务器运维的首要任务是预防问题发生。建议建立定期健康检查机制,包括:CPU使用率监控、内存占用分析、磁盘空间检查和网络连接状态跟踪。系统日志是发现潜在问题的宝库,通过自动化工具对/var/log目录下的关键日志进行实时分析,可以及早发现异常模式,防患于未然。
二、配置自动化备份策略
数据是系统服务的生命线。制定完善的备份策略应包括:全量备份与增量备份结合、异地备份保障数据安全、定期恢复测试验证备份有效性。对于关键配置文件(如nginx.conf、my.cnf等),建议使用版本控制系统进行管理,任何修改都有迹可循。
三、权限管理与安全加固
遵循最小权限原则,为不同服务创建专属用户账号,避免使用root权限运行普通服务。定期更新系统补丁和安全软件,关闭不必要的端口和服务。使用fail2ban等工具防范暴力破解,设置强密码策略和密钥认证,大幅提升系统安全性。
四、性能优化与资源调配
根据服务特点合理分配系统资源至关重要。对于I/O密集型服务,可考虑使用SSD硬盘或调整文件系统参数;对于计算密集型服务,则需要优化CPU调度策略。使用监控工具(如Prometheus、Zabbix)建立性能基线,当指标异常时及时预警。
五、容器化与编排技术应用
Docker等容器技术可以显著提升部署效率和环境一致性。通过容器编排工具(如Kubernetes)实现服务的自动扩缩容、故障自愈,大大减轻运维负担。建议将传统服务逐步迁移至容器环境,但需注意数据持久化和网络配置等细节。
六、文档化与知识沉淀
建立完善的运维文档体系,包括:系统架构图、部署流程、故障处理手册等。每次重大变更或故障处理都应详细记录,形成团队知识库。这不仅有助于新成员快速上手,也能在紧急情况下提供重要参考。
七、监控告警与应急响应
建立多层次监控体系,从硬件层、系统层到应用层全面覆盖。设置合理的告警阈值,避免告警疲劳。同时制定详细的应急响应预案,定期进行故障演练,确保团队在真实故障发生时能够快速、有序地解决问题。
服务器运维是一门实践性极强的技术,需要持续学习和经验积累。上述技巧虽然基础,但若能坚持执行并不断优化,必能显著提升计算机系统服务的稳定性和运维效率。记住,最好的运维是让用户感受不到运维的存在。